日志报警
对于生产环境以及一个有追求的运维人员来说,哪怕是毫秒级别的宕机也是不能容忍的。对基础设施及应用进行适当的日志记录和监控非常有助于解决问题,还可以帮助优化成本和资源,以及帮助检测以后可能会发生的一些问题。使用 Loki 收集日志是否可以根据采集的日志来进行报警呢?答案是肯定的,而且有两种方式可以来实现:Promtail 中的 metrics 阶段和 Loki 的 ruler 组件。
测试应用
比如现在我们有一个如下所的 nginx 应用用于 Loki 日志报警:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| cat > appv1.yml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: appv1
spec:
selector:
matchLabels:
app: appv1
template:
metadata:
labels:
use: test
app: appv1
spec:
containers:
- image: nginx:alpine
name: appv1
command: ["/bin/sh", "-c", "echo '你好, 这是(王先森)APP-v1服务中心'>/usr/share/nginx/html/index.html;nginx -g 'daemon off;'"]
ports:
- containerPort: 80
name: portv1
---
apiVersion: v1
kind: Service
metadata:
name: appv1
spec:
selector:
app: appv1
ports:
- name: http
port: 80
targetPort: portv1
type: NodePort
EOF
|
为方便测试,我们这里使用 NodePort 类型的服务来暴露应用,直接安装即可:
1
2
3
4
5
6
| $ kubectl apply -f appv1.yml
deployment.apps/appv1 unchanged
service/appv1 configured
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
appv1 NodePort 192.168.216.162 <none> 80:32062/TCP 63d
|
我们可以通过如下命令来来模拟每隔 10s 访问 Nginx 应用:
1
| $ while true; do curl --silent --output /dev/null --write-out '%{http_code}' http://10.1.1.120:32062; sleep 10; echo; done
|
Loki告警配置
官方文档 Ruler storage
Grafana Loki 包含一个名为 ruler 的组件。Ruler 负责持续评估一组可配置查询并根据结果执行操作。在通过使用Loki实现高效日志分析和查询 部署的Loki开启了告警配置,我们需要添加新的告警规则。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| apiVersion: v1
kind: ConfigMap
metadata:
name: loki-rule
namespace: logging
labels:
app: loki
data:
nginx.yaml: |
groups:
- name: nginx-rate
rules:
- alert: LokiNginxRate
expr: sum(rate({app="appv1"} |= "error" [1m])) by (job, pod) / sum(rate({app="appv1"}[1m])) by (job, pod) > 0.01
for: 1m
labels:
severity: critical
annotations:
summary: NGINX 实例 {{ $labels.pod }} 的请求错误率过高。
description: high request latency
|
修改StatefulSets
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| kubectl edit -n logging statefulsets.apps loki
volumeMounts:
- name: config
mountPath: /etc/loki/config/loki.yaml
subPath: loki.yaml
- name: rule
mountPath: /etc/loki/rules/fake
..........
volumes:
- name: config
configMap:
defaultMode: 0640
name: loki
- name: rule
configMap:
defaultMode: 0640
name: loki-rule
|
检查告警
1
2
3
4
5
6
| # 查看 loki 日志,日志关键字
$ kubectl logs -f -n logging loki-0 loki |grep rule
level=info ts=2023-12-20T06:48:05.448914358Z caller=mapper.go:47 msg="cleaning up mapped rules directory" path=/data/loki/rules-temp
level=info ts=2023-12-20T06:48:05.458968739Z caller=module_service.go:82 msg=initialising module=ruler
level=info ts=2023-12-20T06:48:05.459017096Z caller=ruler.go:528 msg="ruler up and running"
level=info ts=2023-12-20T06:48:05.460113433Z caller=mapper.go:160 msg="updating rule file" file=/data/loki/rules-temp/fake/nginx.yaml
|
上面日志显示,loki已经更新新的规则文件。
如果文件的格式有问题,将无法加载文件,日志会显示错误原因。
每次更新rule file,需要查看loki日志,确认配置更新。
告警配置规则
Loki 的 rulers 规则和结构与 Prometheus 是完全兼容,唯一的区别在于查询语句(LogQL)不同,在 Loki 中我们用 LogQL 来查询日志,一个典型的 rules 配置文件如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| groups:
- name: xxxx
rules:
- alert: xxxx
expr: xxxx
[ for: | default = 0s ]
labels:
[ : ]
annotations:
[ : ]
|
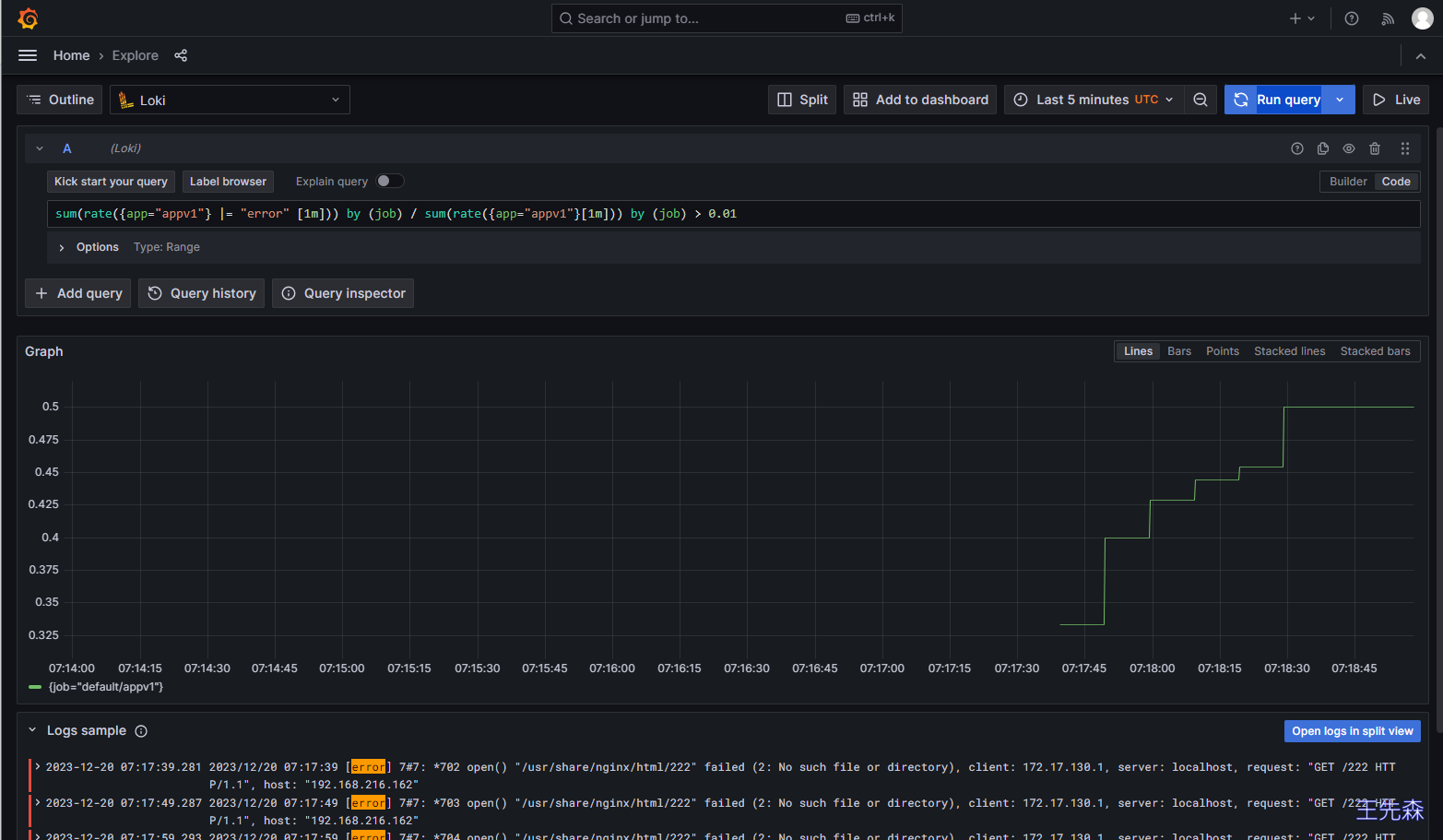
比如我们这里配置的规则 sum(rate({app="appv1"} |= "error" [1m])) by (job) / sum(rate({app="appv1"}[1m])) by (job) > 0.01 表示通过日志查到 nginx 日志的错误率大于 1%就触发告警:

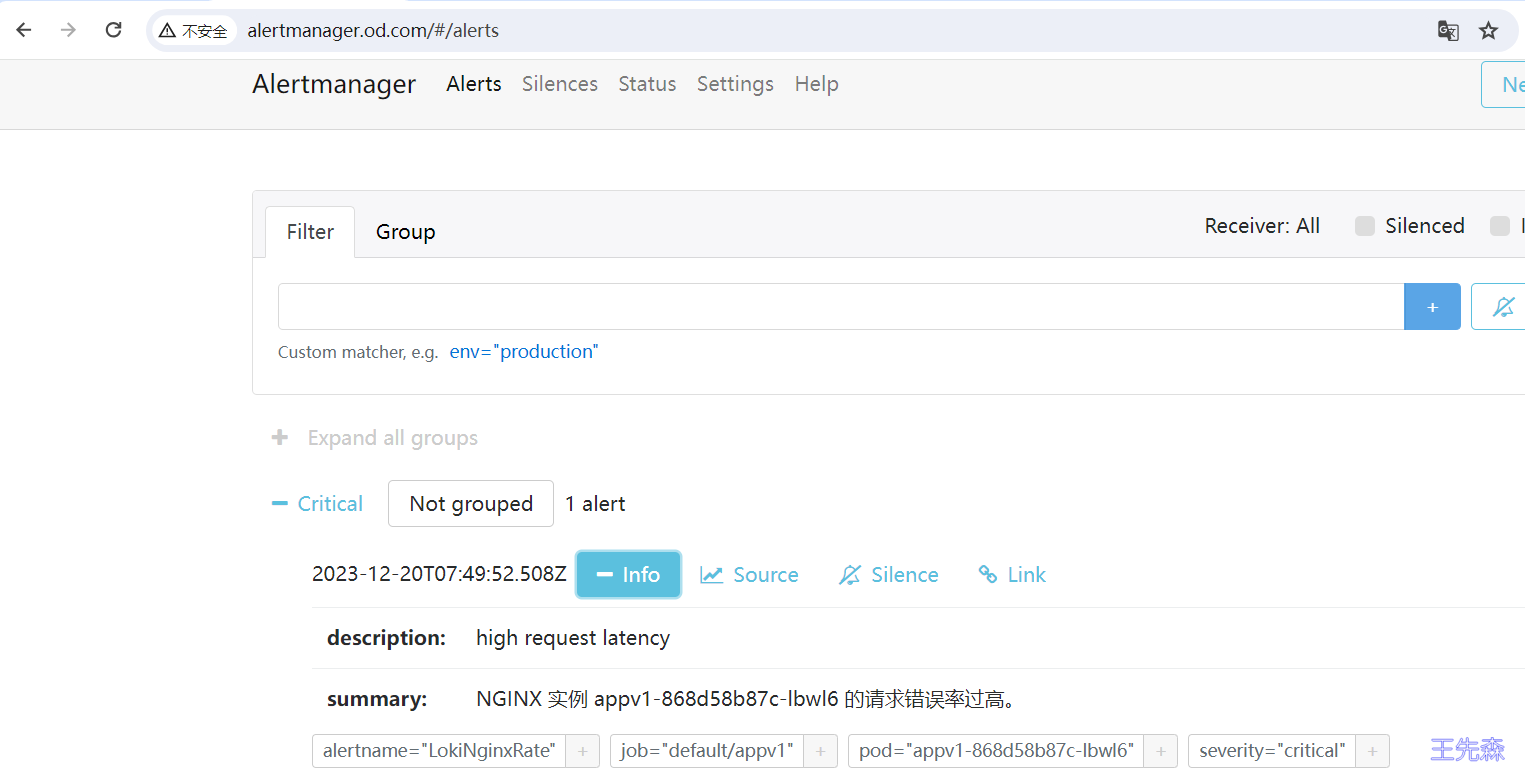
同样在 1m 之内如果持续超过阈值,则会真正触发报警规则,触发后我们在 Alertmanager 也可以看到对应的报警信息了: