Prometheus Operator介绍 Prometheus Operator :为监控 Kubernetes 资源和 Prometheus 实例的管理提供了简单的定义,简化在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群。
Prometheus Operator 的核心特性是 watch Kubernetes API 服务器对特定对象的更改,为 Kubernetes 提供了对 Prometheus 机器相关监控组件的本地部署和管理方案,该项目的目的是为了简化和自动化基于 Prometheus 的监控栈配置,主要包括以下几个功能:
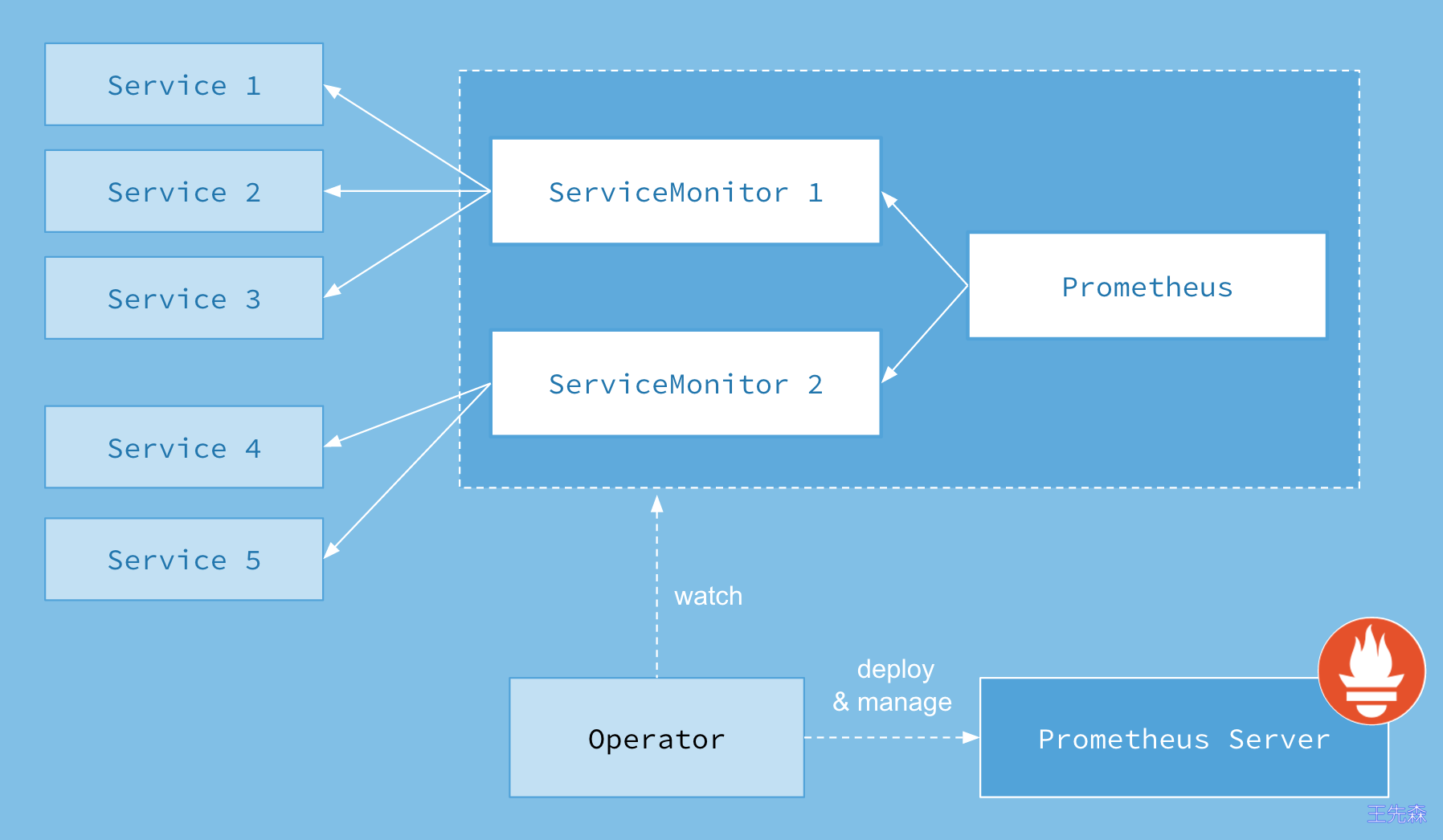
Kubernetes 自定义资源:使用 Kubernetes CRD 来部署和管理 Prometheus、Alertmanager 和相关组件。 简化的部署配置:直接通过 Kubernetes 资源清单配置 Prometheus,比如版本、持久化、副本、保留策略等等配置。 Prometheus 监控目标配置:基于熟知的 Kubernetes 标签查询自动生成监控目标配置,无需学习 Prometheus 特地的配置。 Prometheus Operator 的架构图:
上图是 Prometheus-Operator 官方提供的架构图,各组件以不同的方式运行在 Kubernetes 集群中,其中 Operator 是最核心的部分,作为一个控制器,他会去创建 Prometheus、ServiceMonitor、AlertManager 以及 PrometheusRule 等 CRD 资源对象,然后会一直 Watch 并维持这些资源对象的状态。
最新版本的 Operator 中提供了一下几个 CRD 资源对象:
Prometheus:配置 Prometheus statefulset 及 Prometheus 的一些配置。ServiceMonitor:用于通过 Service 对 K8S 中的资源进行监控,推荐首选 ServiceMonitor. 它声明性地指定了 Kubernetes service 应该如何被监控。PodMonitor:用于对 Pod 进行监控,推荐首选 ServiceMonitor. PodMonitor 声明性地指定了应该如何监视一组 pod。Probe:它声明性地指定了应该如何监视 ingress 或静态目标组. 一般用于黑盒监控.PrometheusRule:用于管理 Prometheus 告警规则;它定义了一套所需的 Prometheus 警报和/或记录规则。可以被 Prometheus 实例挂载使用。Alertmanager:配置 AlertManager statefulset 及 AlertManager 的一些配置。AlertmanagerConfig:用于管理 AlertManager 配置文件;它声明性地指定 Alertmanager 配置的子部分,允许将警报路由到自定义接收器,并设置禁止规则。ThanosRuler:管理 ThanosRuler deployment;Prometheus Operator安装 为了使用 Prometheus-Operator,这里直接使用 kube-prometheus 这个项目来进行安装,该项目和 Prometheus-Operator 的区别就类似于 Linux 内核和 CentOS/Ubuntu 这些发行版的关系,真正起作用的是 Operator 去实现的,而 kube-prometheus 只是利用 Operator 编写了一系列常用的监控资源清单。不过需要注意 Kubernetes 版本和 kube-prometheus 的兼容:
这里我的 k8s 测试集群版本是 1.23.4,先 clone 项目代码,部署 release-0.11 版本的 kube-prometheus
1 2 git clone https://github.com/prometheus-operator/kube-prometheus -b release-0.11 cd kube-prometheus
首先创建需要的命名空间和 CRDs,等待它们可用后再创建其余资源:
1 2 3 4 5 6 7 8 9 10 $ kubectl apply -f manifests/setup customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created namespace/monitoring created The CustomResourceDefinition "prometheuses.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
可以看到安装过程中会提示 Too long: must have at most 262144 bytes,只需要将 kubectl apply 改成 kubectl create 即可:
1 2 3 4 5 6 7 8 9 10 11 12 $ kubectl create -f manifests/setup $ kubectl get crd |grep coreos alertmanagerconfigs.monitoring.coreos.com 2023-11-14T07:43:53Z alertmanagers.monitoring.coreos.com 2023-11-14T07:43:53Z podmonitors.monitoring.coreos.com 2023-11-14T07:43:53Z probes.monitoring.coreos.com 2023-11-14T07:43:53Z prometheusagents.monitoring.coreos.com 2023-11-14T07:44:05Z prometheuses.monitoring.coreos.com 2023-11-14T07:44:05Z prometheusrules.monitoring.coreos.com 2023-11-14T07:43:53Z scrapeconfigs.monitoring.coreos.com 2023-11-14T07:43:53Z servicemonitors.monitoring.coreos.com 2023-11-14T07:43:54Z thanosrulers.monitoring.coreos.com 2023-11-14T07:43:54Z
这会创建一个名为 monitoring 的命名空间,当声明完 CRD 过后,就可以来自定义资源清单了,但是要让声明的自定义资源对象生效就需要安装对应的 Operator 控制器,在 manifests 目录下面就包含了 Operator 的资源清单以及各种监控对象声明,比如 Prometheus、Alertmanager 等,直接应用即可:
1 $ kubectl apply -f manifests/
不过需要注意有一些资源的镜像来自于 k8s.gcr.io,如果不能正常拉取,则可以将镜像替换成可拉取的:
prometheusAdapter-deployment.yaml:将 image: k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.11.1 替换为 wangxiansen/prometheus-adapter:v0.11.1kubeStateMetrics-deployment.yaml:将 image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.9.2 替换为 wangxiansen/kube-state-metrics:v2.9.2这会自动安装 prometheus-operator、node-exporter、kube-state-metrics、grafana、prometheus-adapter 以及 prometheus 和 alertmanager 等大量组件,如果没成功可以多次执行上面的安装命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 kubectl get pods -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 4d20h blackbox-exporter-6cd58cb8d8-8vk8c 3/3 Running 24 (6d1h ago) 40d grafana-8f858b985-976bp 1/1 Running 0 4d21h kube-state-metrics-666cb85f4c-298nz 3/3 Running 26 (6d1h ago) 40d node-exporter-hckm7 2/2 Running 12 (6d1h ago) 40d node-exporter-jgglz 2/2 Running 10 (6d1h ago) 40d node-exporter-s24x9 2/2 Running 15 (6d1h ago) 40d prometheus-adapter-6fbbcc44df-6cqsj 1/1 Running 3 (6d1h ago) 37d prometheus-k8s-0 2/2 Running 11 (6d1h ago) 40d prometheus-operator-5ff845f4f6-89dwp 2/2 Running 13 (6d1h ago) 40d [root@k8s-master1 ~]# kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main ClusterIP 192.168.153.119 <none> 9093/TCP,8080/TCP 40d alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 40d blackbox-exporter ClusterIP 192.168.119.161 <none> 9115/TCP,19115/TCP 40d grafana ClusterIP 192.168.151.51 <none> 3000/TCP 40d kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 40d node-exporter ClusterIP None <none> 9100/TCP 40d prometheus-adapter ClusterIP 192.168.91.7 <none> 443/TCP 40d prometheus-k8s ClusterIP 192.168.78.153 <none> 9090/TCP,8080/TCP 40d prometheus-operated ClusterIP None <none> 9090/TCP 40d prometheus-operator ClusterIP None <none> 8443/TCP 40d
注意: 我这里由于资源问题,都是使用单个副本数量。
可以看到上面针对 grafana、alertmanager 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,当然如果想要在外网访问这两个服务的话可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service。NodePort类型不用多说。这里就现在使用Ingress创建。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: prometheus-web namespace: monitoring spec: entryPoints: - web routes: - match: Host(`prometheus.od.com`) kind: Rule services: - name: prometheus-k8s port: 9090 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: alertmanager-web namespace: monitoring spec: entryPoints: - web routes: - match: Host(`alertmanager.od.com`) kind: Rule services: - name: alertmanager-main port: 9093 --- apiVersion: traefik.containo.us/v1alpha1 kind: IngressRoute metadata: name: grafana-web namespace: monitoring spec: entryPoints: - web routes: - match: Host(`grafana.od.com`) kind: Rule services: - name: grafana port: 3000
创建完成后通过浏览器打开 http://grafana.od.com 、http://alertmanager.od.com 、http://prometheus.od.com
grafana 默认用户名密码为 admin/admin
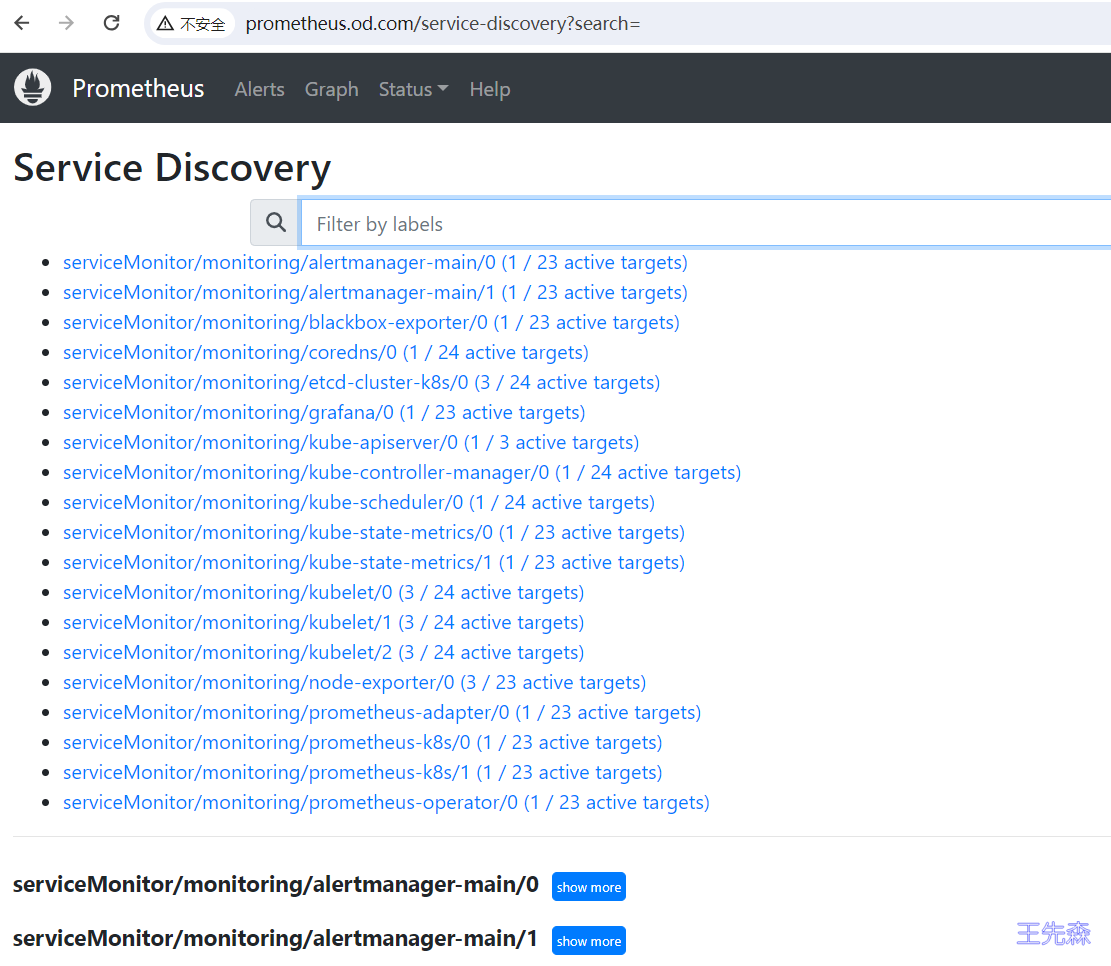
查看 prometheus 的服务发现页面
数据持久化 prometheus prometheus 默认的数据文件使用的是 emptydir 方式进行的持久化, 我们改为 本地存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: local-storage provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer --- apiVersion: v1 kind: PersistentVolume metadata: name: prometheus-local labels: app: prometheus app.kubernetes.io/name: prometheus spec: accessModes: - ReadWriteOnce capacity: storage: 20Gi storageClassName: local-storage local: path: /data/k8s/prometheus nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-master1 persistentVolumeReclaimPolicy: Retain
然后在修改 manifests/prometheus-prometheus.yaml在文件最后新增配置
1 2 3 4 5 6 7 8 9 10 11 retention: 10d storage: volumeClaimTemplate: spec: storageClassName: local-storage selector: matchLabels: app: prometheus resources: requests: storage: 5Gi
grafana grafana 就是一个普通的 deployment 应用, 直接修改 yaml 中的 volume 配置即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 spec: nodeName: k8s-node2 initContainers: - name: fix-permissions image: busybox:latest securityContext: privileged: true runAsGroup: 0 runAsNonRoot: false runAsUser: 0 command: - sh - -c - >- id; ls -la /var/lib/grafana; chown -R 65534:65534 /var/lib/grafana volumeMounts: - mountPath: /var/lib/grafana name: grafana-storage ...... volumes: - name: grafana-storage hostPath: path: /data/nfs-volume/grafana