Grafana的介绍与使用
简介
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。目前使用grafana的公司有很多,如paypal、ebay、intel等。
七大特点
①可视化:快速和灵活的客户端图形具有多种选项。面板插件为许多不同的方式可视化指标和日志。
②报警:可视化地为最重要的指标定义警报规则。Grafana将持续评估它们,并发送通知。
③通知:警报更改状态时,它会发出通知。接收电子邮件通知。
④动态仪表盘:使用模板变量创建动态和可重用的仪表板,这些模板变量作为下拉菜单出现在仪表板顶部。
⑤混合数据源:在同一个图中混合不同的数据源!可以根据每个查询指定数据源。这甚至适用于自定义数据源。
⑥注释:注释来自不同数据源图表。将鼠标悬停在事件上可以显示完整的事件元数据和标记。
⑦过滤器:过滤器允许您动态创建新的键/值过滤器,这些过滤器将自动应用于使用该数据源的所有查询。
Grafana安装部署
准备镜像
1
2
3
| [root@k8s-dns ]# docker pull grafana/grafana:7.3.3
[root@k8s-dns ]# docker tag grafana/grafana:7.3.3 harbor.od.com/infra/grafana:v7.3.3
[root@k8s-dns ]# docker push harbor.od.com/infra/grafana:v7.3.3
|
资源配置清单
1
2
| [root@k8s-dns ~]# mkdir /var/k8s-yaml/grafana
[root@k8s-dns ~]# cd /var/k8s-yaml/grafana
|
vim /var/k8s-yaml/grafana/deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
name: grafana
namespace: infra
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 7
selector:
matchLabels:
name: grafana
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: grafana
name: grafana
spec:
containers:
- name: grafana
image: harbor.od.com/infra/grafana:v7.3.3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /var/lib/grafana
name: data
imagePullSecrets:
- name: harbor
securityContext:
runAsUser: 0
volumes:
- nfs:
server: k8s-dns
path: /data/nfs-volume/grafana
name: data
|
vim /var/k8s-yaml/grafana/rbac.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
rules:
- apiGroups:
- "*"
resources:
- namespaces
- deployments
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: grafana
subjects:
- kind: User
name: k8s-node
|
vim /var/k8s-yaml/grafana/svc.yaml
1
2
3
4
5
6
7
8
9
10
11
12
| apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: infra
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 3000
selector:
app: grafana
|
vim /var/k8s-yaml/grafana/ingress.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: infra
spec:
rules:
- host: grafana.od.com
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000
|
创建挂载目录、DNS解析
1
2
3
4
| mkdir /data/nfs-volume/grafana
vi /var/named/chroot/etc/od.com.zone
...
grafana A 10.1.1.50
|
应用资源配置清单
在任意一台k8s运算节点执行:
1
2
3
4
| kubectl apply -f http://k8s-yaml.od.com/grafana/rbac.yaml
kubectl apply -f http://k8s-yaml.od.com/grafana/deployment.yaml
kubectl apply -f http://k8s-yaml.od.com/grafana/svc.yaml
kubectl apply -f http://k8s-yaml.od.com/grafana/ingress.yaml
|
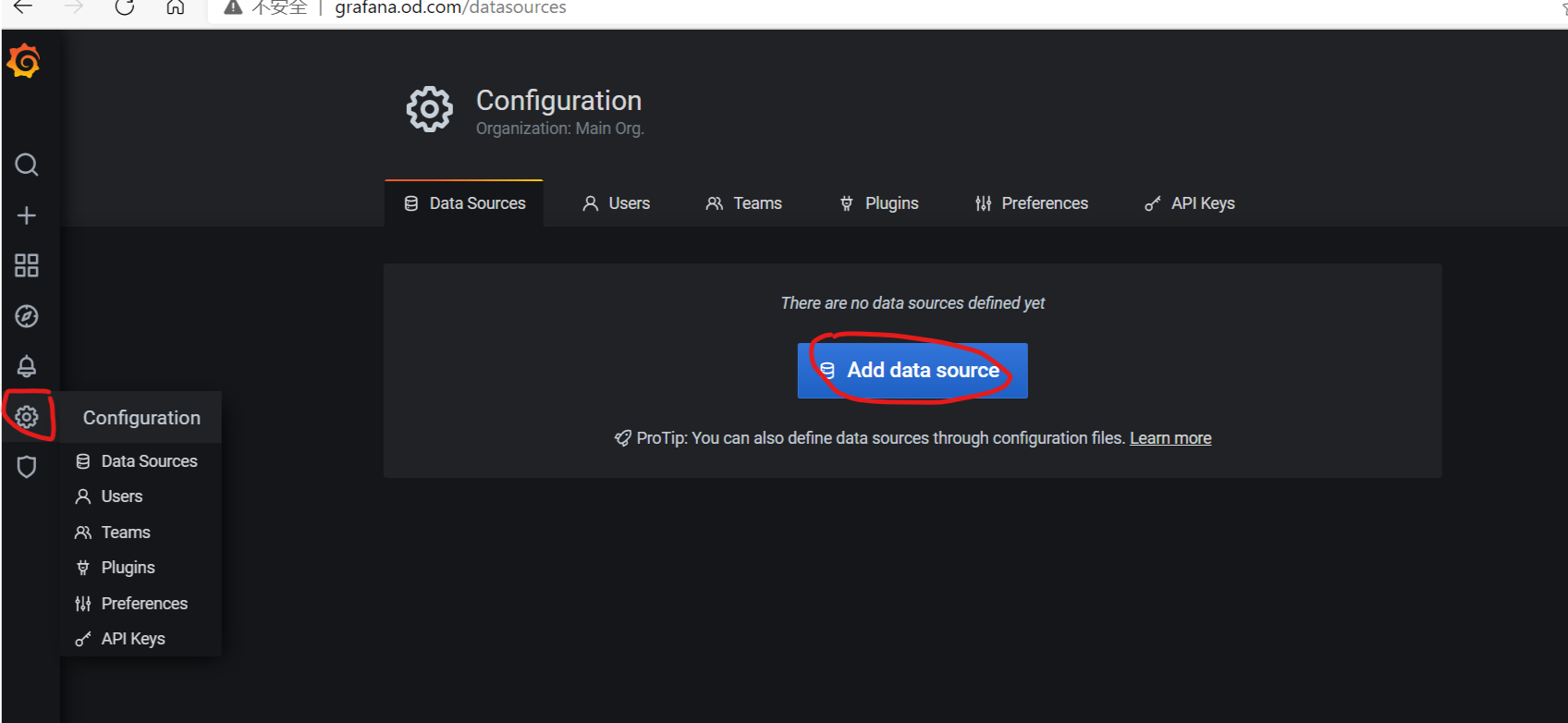
浏览器访问:
http://grafana.od.com

安装插件
安装方法1:
进入容器装插件
1
2
3
4
5
6
7
| kubectl exec -it -n infra grafana-85885b7876-7cc4r -- /bin/bash
grafana-cli plugins install grafana-kubernetes-app
grafana-cli plugins install grafana-clock-panel
grafana-cli plugins install grafana-piechart-panel
grafana-cli plugins install briangann-gauge-panel
grafana-cli plugins install natel-discrete-panel
|
安装方法2:
/data/nfs-volume/grafana/plugins目录下
1
2
3
4
5
| wget https://grafana.com/api/plugins/grafana-kubernetes-app/versions/1.0.1/download -O grafana-kubernetes-app.zip
wget https://grafana.com/api/plugins/grafana-clock-panel/versions/1.0.2/download -O grafana-clock-panel.zip
wget https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.3.6/download -O grafana-piechart-panel.zip
wget https://grafana.com/api/plugins/briangann-gauge-panel/versions/0.0.6/download -O briangann-gauge-panel.zip
wget https://grafana.com/api/plugins/natel-discrete-panel/versions/0.0.9/download -O natel-discrete-panel.zip
|
下载之后解压并改名即可。插件装完之后重启grafana生效
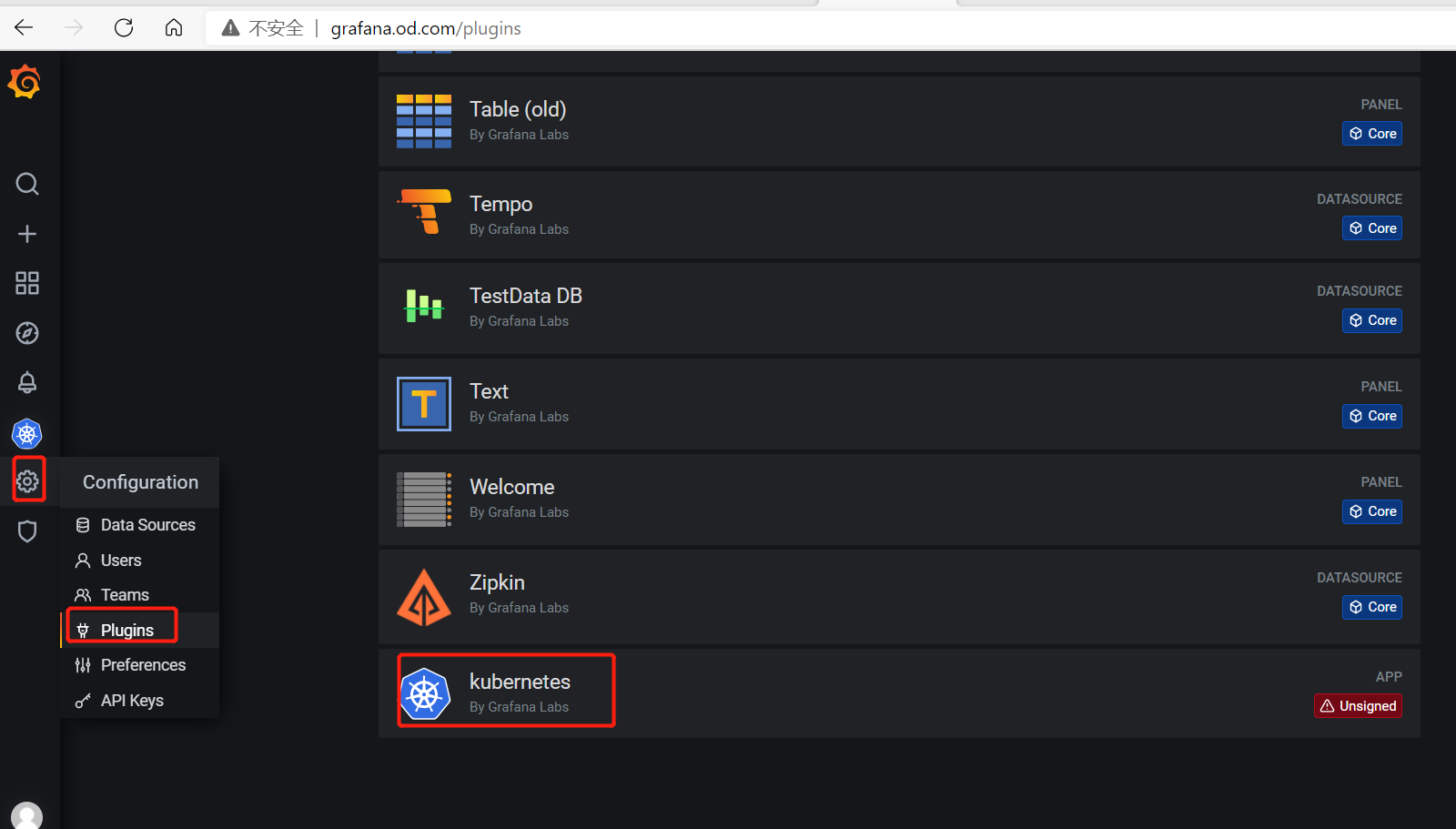
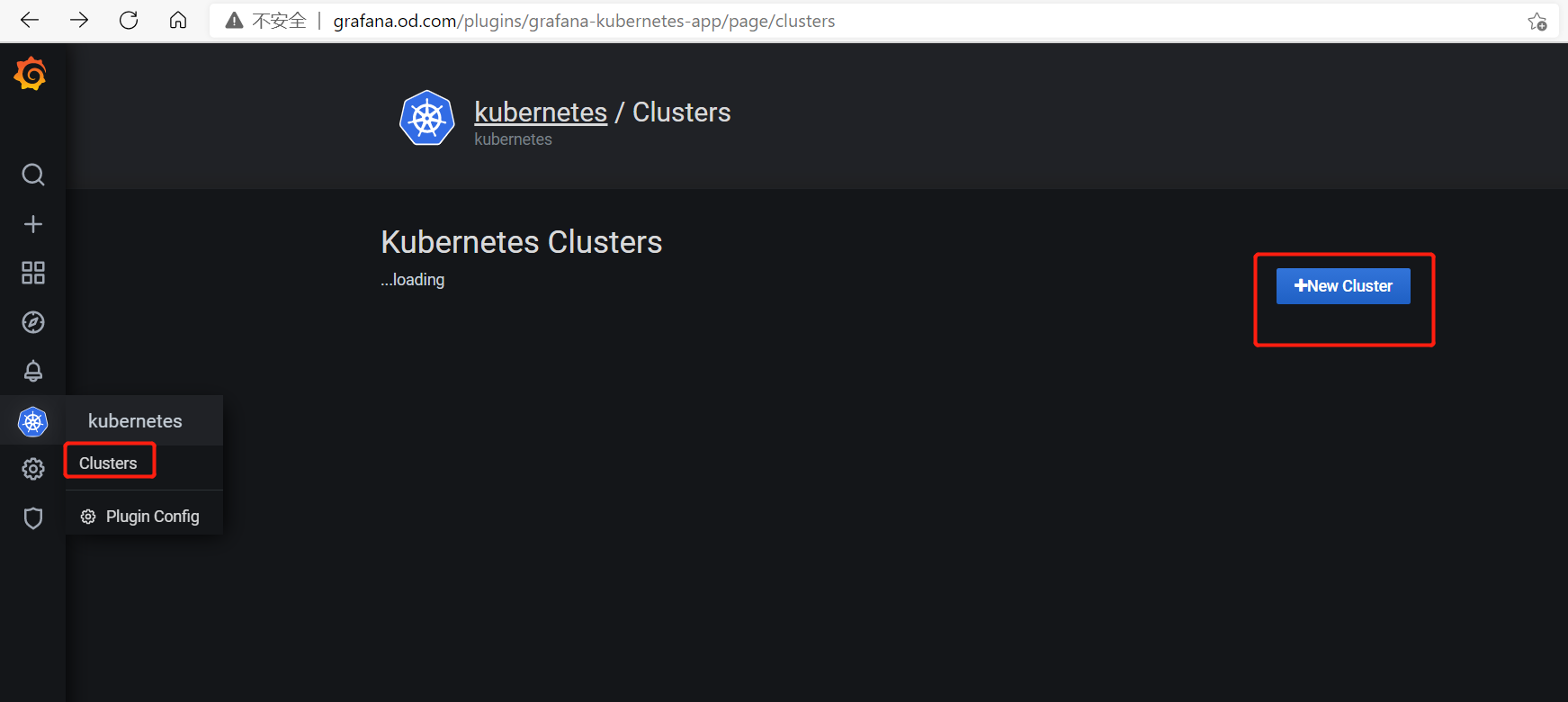
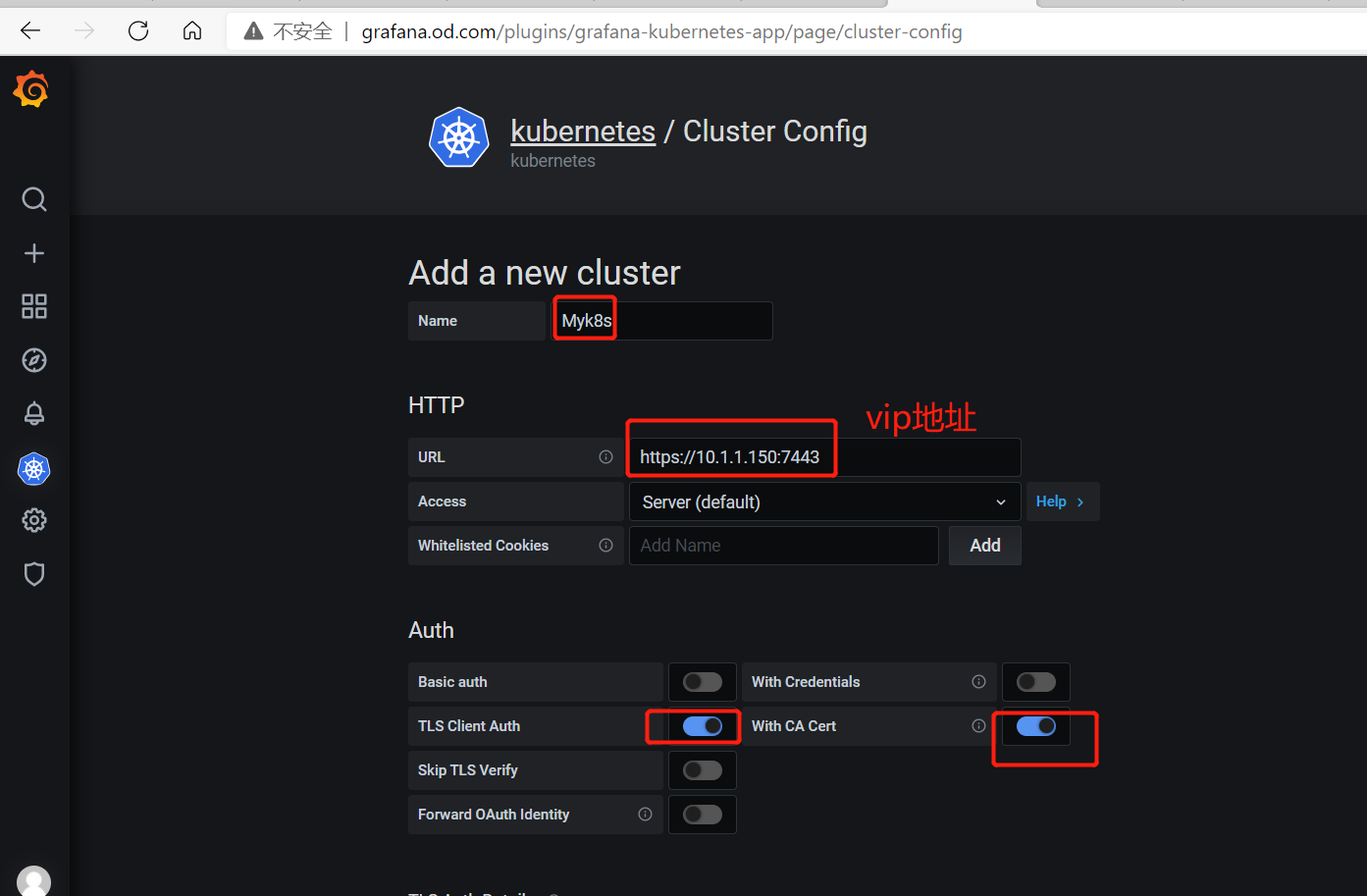
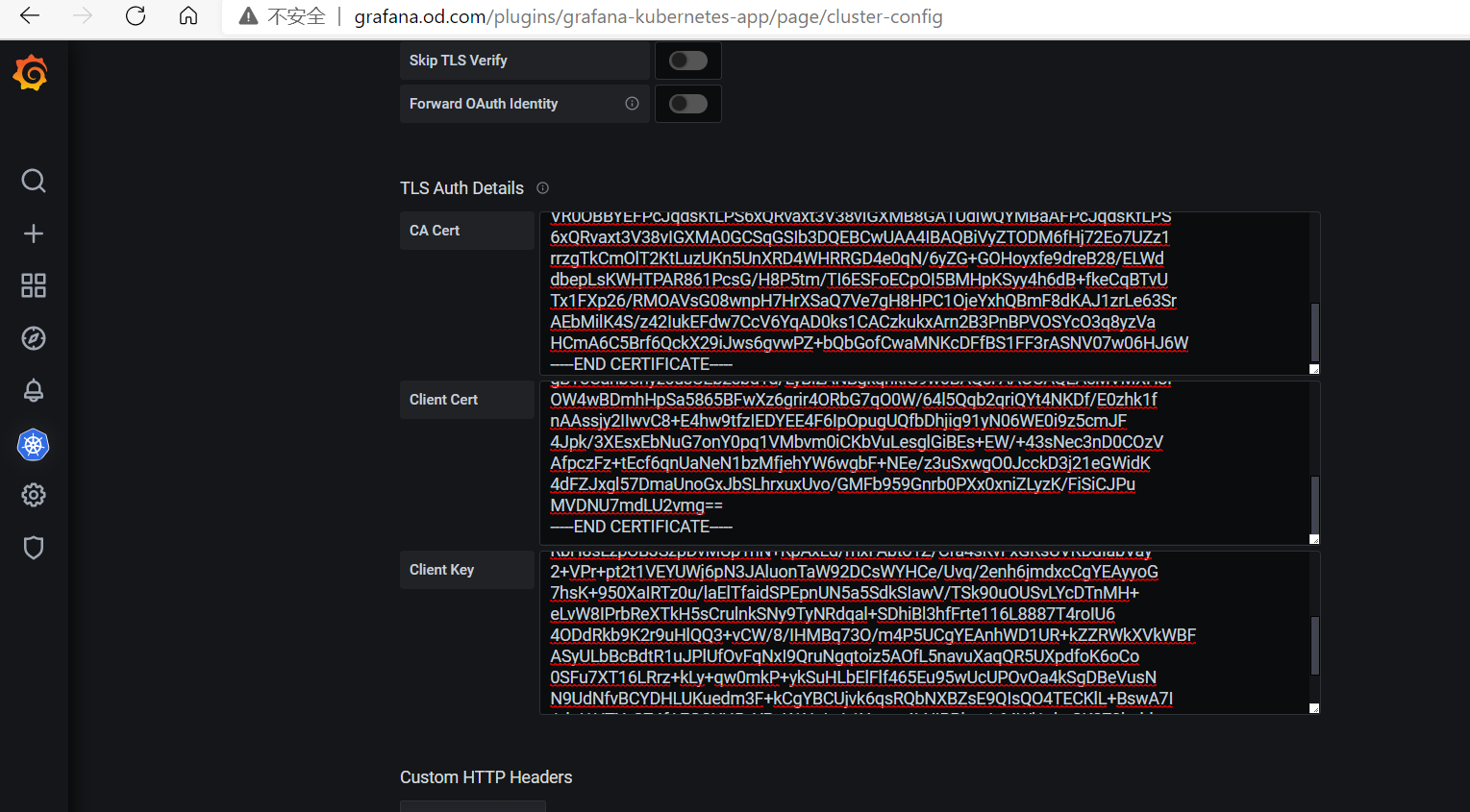
配置grafana支持K8S
激活kubernetes插件
查看出图
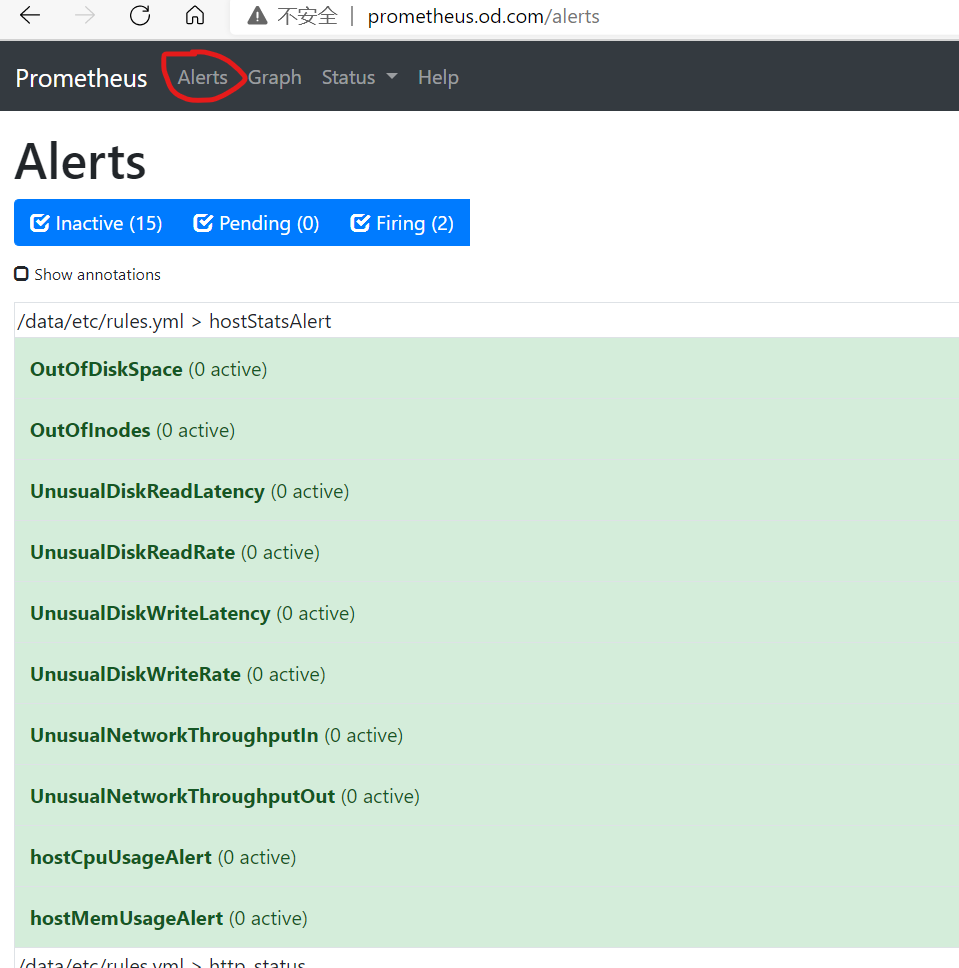
alertmanager告警
准备镜像
1
2
3
| docker pull docker.io/prom/alertmanager:v0.14.0
docker tag docker.io/prom/alertmanager:v0.14.0 harbor.od.com/infra/alertmanager:v0.14.0
docker push harbor.od.com/infra/alertmanager:v0.14.0
|
准备资源配置清单
1
2
| [root@k8s-dns ~]# mkdir /var/k8s-yaml/alertmanager
[root@k8s-dns ~]# cd /var/k8s-yaml/alertmanager
|
vim /var/k8s-yaml/alertmanager/deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: infra
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: harbor.od.com/infra/alertmanager:v0.14.0
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: alertmanager-cm
mountPath: /etc/alertmanager
volumes:
- name: alertmanager-cm
configMap:
name: alertmanager-config
imagePullSecrets:
- name: harbor
|
vim /var/k8s-yaml/alertmanager/configmap.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: infra
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'wang_xiansen0@163.com'
smtp_auth_username: 'wang_xiansen0@163.com'
smtp_auth_password: 'xxxxxx'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
group_interval: 5m
repeat_interval: 5m
receiver: default
receivers:
- name: 'default'
email_configs:
- to: '1767361332@qq.com'
send_resolved: true
|
vim /var/k8s-yaml/alertmanager/svc.yaml
1
2
3
4
5
6
7
8
9
10
11
| apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: infra
spec:
selector:
app: alertmanager
ports:
- port: 80
targetPort: 9093
|
应用资源配置清单
在任意一台k8s运算节点执行:
1
2
3
| kubectl apply -f http://k8s-yaml.od.com/alertmanager/configmap.yaml
kubectl apply -f http://k8s-yaml.od.com/alertmanager/deployment.yaml
kubectl apply -f http://k8s-yaml.od.com/alertmanager/svc.yaml
|
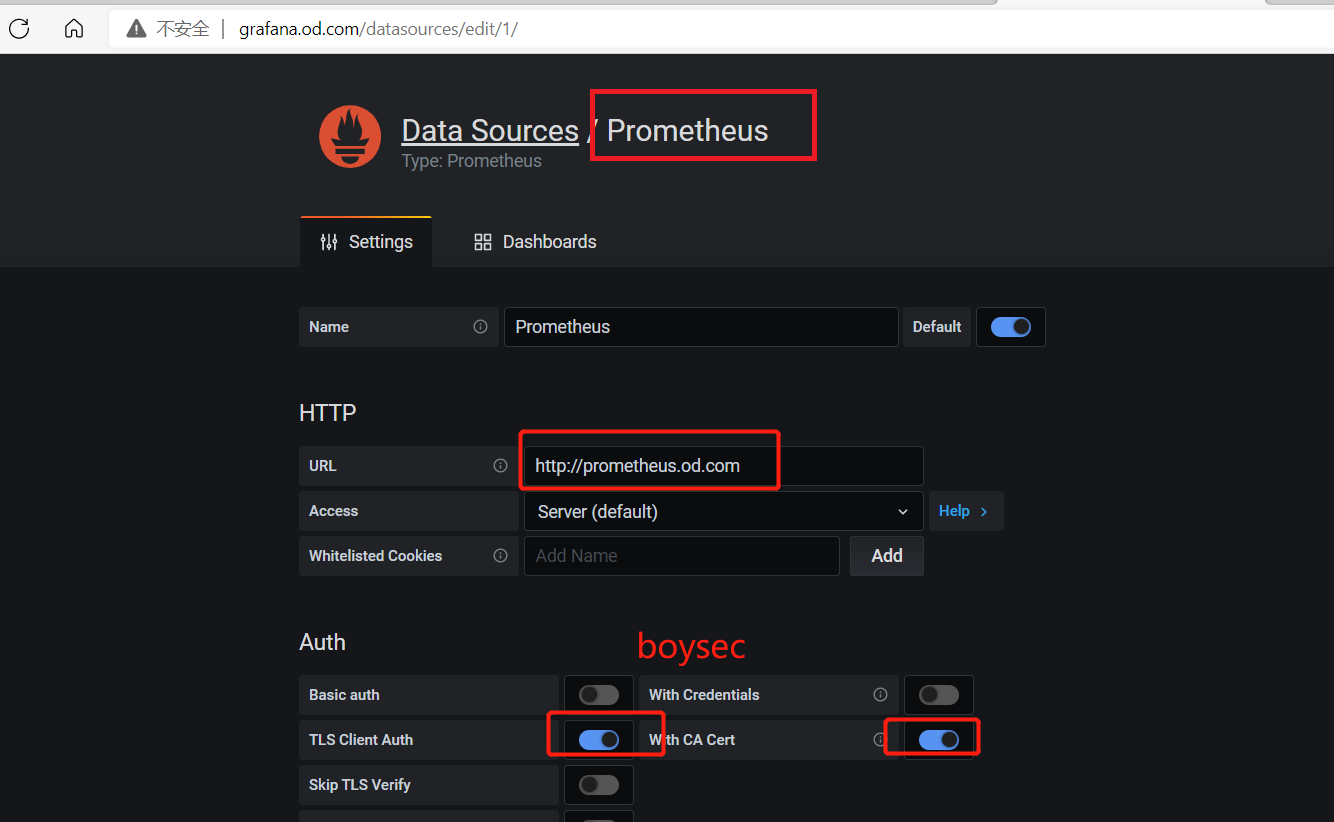
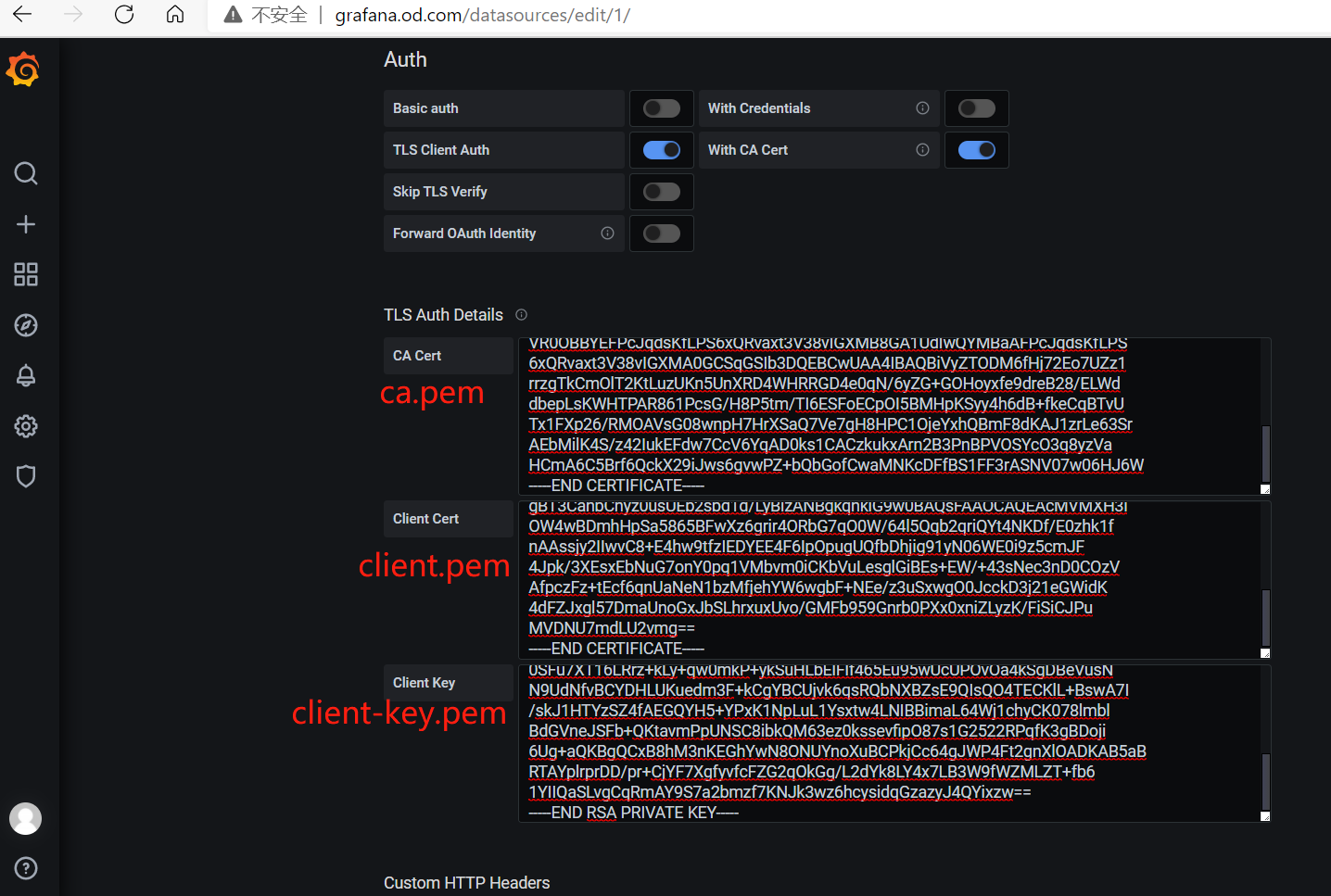
修改Prometheus配置
添加报警规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
| [root@k8s-dns ~]# vim /data/nfs-volume/prometheus/etc/rules.yml
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)"
- alert: OutOfInodes
expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of inodes (instance {{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})"
- alert: OutOfDiskSpace
expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputOut
expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadRate
expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read rate (instance {{ $labels.instance }})"
description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskWriteRate
expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write rate (instance {{ $labels.instance }})"
description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadLatency
expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})"
- alert: UnusualDiskWriteLatency
expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})"
- name: http_status
rules:
- alert: ProbeFailed
expr: probe_success == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe failed (instance {{ $labels.instance }})"
description: "Probe failed (current value: {{ $value }})"
- alert: StatusCode
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 1m
labels:
severity: error
annotations:
summary: "Status Code (instance {{ $labels.instance }})"
description: "HTTP status code is not 200-399 (current value: {{ $value }})"
- alert: SslCertificateWillExpireSoon
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 5m
labels:
severity: warning
annotations:
summary: "SSL certificate will expire soon (instance {{ $labels.instance }})"
description: "SSL certificate expires in 30 days (current value: {{ $value }})"
- alert: SslCertificateHasExpired
expr: probe_ssl_earliest_cert_expiry - time() <= 0
for: 5m
labels:
severity: error
annotations:
summary: "SSL certificate has expired (instance {{ $labels.instance }})"
description: "SSL certificate has expired already (current value: {{ $value }})"
- alert: BlackboxSlowPing
expr: probe_icmp_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow ping (instance {{ $labels.instance }})"
description: "Blackbox ping took more than 2s (current value: {{ $value }})"
- alert: BlackboxSlowRequests
expr: probe_http_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow requests (instance {{ $labels.instance }})"
description: "Blackbox request took more than 2s (current value: {{ $value }})"
- alert: PodCpuUsagePercent
expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"
|
修改配置文件
1
2
3
4
5
6
7
| #在最后添加
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files:
- "/data/etc/rules.yml"
|
平滑重启Prometheus
1
2
3
| [root@k8s-node01 ~]# ps -aux |grep prometheus
root 102504 2.9 16.3 1517580 330932 ? Ssl 17:33 2:00 /bin/prometheus --config.file=/data/etc/prometheus.yml --storage.tsdb.path=/data/prom-db --storage.tsdb.retention=72h --storage.tsdb.min-block-duration=10m
[root@k8s-node01 ~]# kill -SIGHUP 102504
|
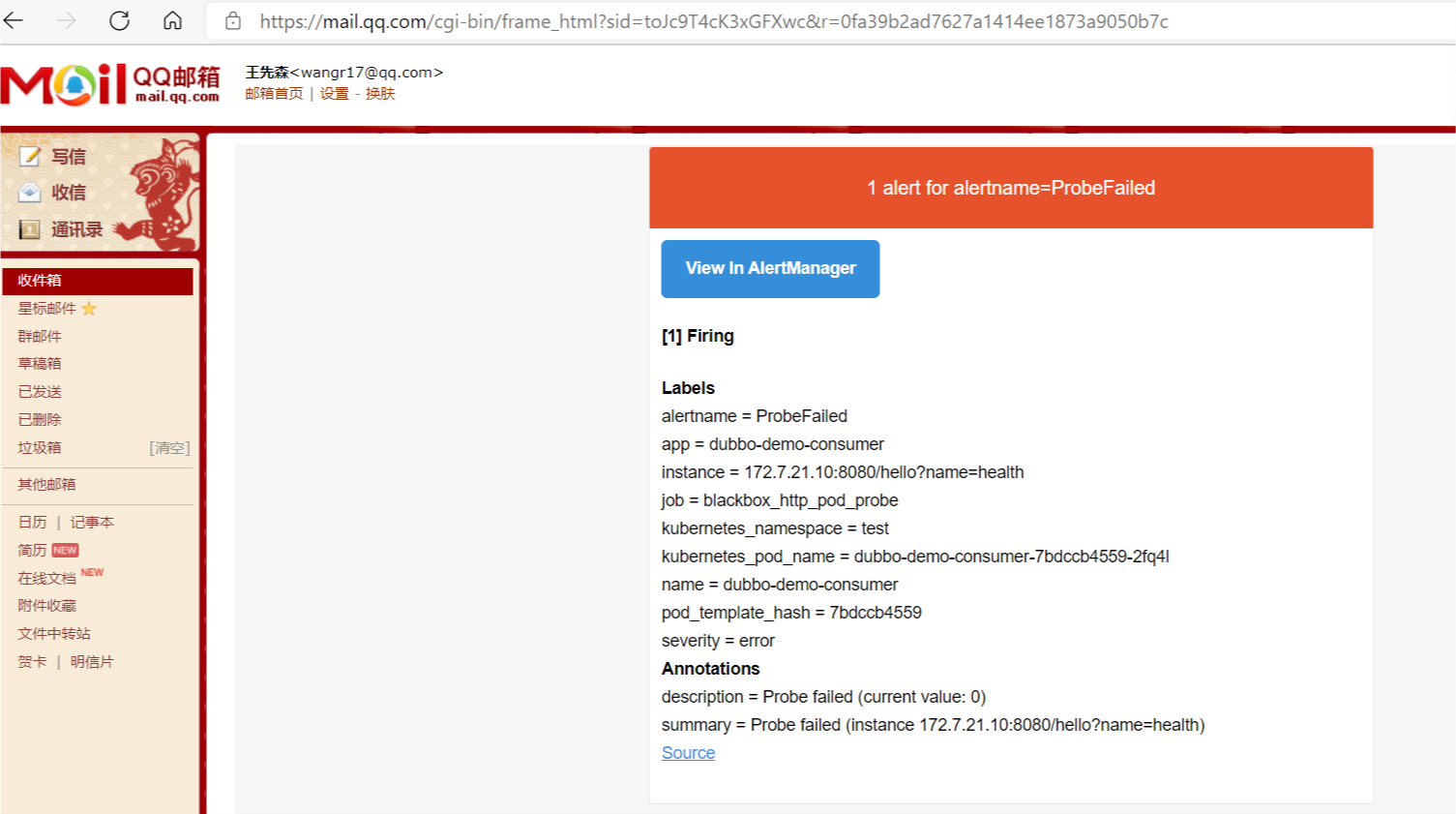
验证是否重启成功
测试邮件告警